
RPAで請求書処理を自動化したいのですが、内容を上手く読み取れません

そんな時はUiPathのDocument Understandingがお勧めです!
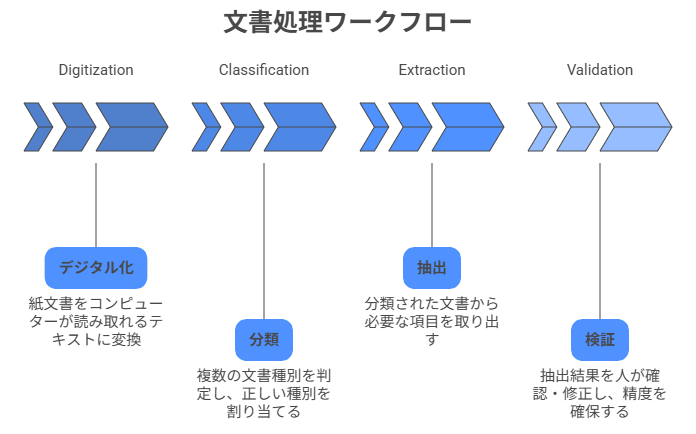
Document Understandingは、UiPath(RPAツール)の製品の1つで、文書をデータ化する一連の処理を全て担ってくれるサービスです。具体的には、文書のデジタル化、分類、データ抽出、そして人による確認まで、文書処理に必要な4つのステップをカバーします。
本記事では、DUの概要からモダン/クラシックの違い、代表的なユースケース、コストの考え方まで、初心者向けに徹底解説します。
Document Understandingとは
Document Understanding(以下DU)は、UiPathが提供する文書処理基盤です。文書から必要な情報を取り出して業務で使える形にするための、一連の仕組み全体を指します。
4つの基本機能
DUは、次の4つの基本機能で構成されています。
- デジタル化:紙や画像の文書をコンピューターが読み取れるテキストに変換する工程です。
- 分類:複数の文書種別が混在するファイルの中から、それぞれの種別を判定します。
- 抽出:分類された文書から、必要な項目(金額、日付、取引先など)を取り出します。
- 検証:信頼度が低い抽出結果を人が確認・修正する工程です。

PDF・画像の読み取りから抽出、検証まで全て任せられるんですね!
文書処理に必要な機能はほぼ全て揃っている印象です
対応範囲を広げる代表的な2つのアプローチ
4つの基本能力に加え、DUには「事前学習済みモデルのカスタム学習」と「生成AI抽出器」という2つのアプローチが用意されています。処理したいドキュメントの種類や性質によって、どちらを使うかを選ぶことになります。
これらはドキュメントの「分類」と「抽出」フェーズで使用されます。
機械学習モデルによるカスタム学習
機械学習モデルとは、ドキュメントのサンプルをもとに「どこに何の情報があるか」を学習し、新しいドキュメントでも同じパターンを自動で見つけられるようにしたAIのことです。たとえば請求書のサンプルに「この数字が請求金額」「この文字列が取引先名」とラベル付けして学習させると、未知の請求書でも同じ項目を自動で抽出できるようになります。
自分で育てられるAIってことですね
UiPathには請求書・領収書・IDカードなど50種類以上の事前学習済みモデルが提供されており、追加学習なしにすぐ使い始められます。既存モデルが対応していないドキュメントについては、自社のデータを使ってモデルを学習させることで、対応範囲を広げられます。
生成AIによる柔軟な対応
生成AI抽出器は、自然言語のプロンプト(請求金額は何円?など)を使って情報を取り出す仕組みです。レイアウトが一定でない文書や、MLモデルが苦手とするケースへの補完として活用できます。
個人的には、まず機械学習モデルで分類・抽出を行い、機械学習モデルが自信が無いと判断した項目を、生成AIモデルで補完する使い方が良いと思います。
Document Understandingができること
DUが対応できる主な処理を紹介します。前提として、処理対象は主に「構造化・半構造化」された文書です。
例えば契約書のような非構造化データは、IXPという別の製品の方が適しています。
- 文書の種別を自動で判別する(請求書なのか、領収書なのかを分ける)
- 必要な項目を自動で抽出する(金額、日付、取引先名など)
- 信頼度が低い箇所だけ人が確認・検証する
- 請求書・領収書・本人確認書類など、定型〜半定型の文書処理を効率化する
- 事前学習済みのモデル(請求書、領収書、IDカードなど)を活用して、学習コストを抑えて始められる
ビジネスシーンでは誤入力が怖いので、信頼度に基づいて人間にエスカレーションする「検証」機能は特に重要です
Document Understandingができないこと・注意点
DUは文書処理を自動化する仕組みですが、すべての文書を無条件に高精度で処理できるわけではありません。
苦手な状況と設計上の注意点
OCR品質が低い文書
解像度が粗いスキャンや手書きが多い文書は、デジタル化の精度自体が下がりやすいです。OCRで読み取れない文字が増えると、後続の抽出精度にも直接影響します。入力文書の品質を確認することが重要です。
レイアウトにばらつきがある文書
ページごとにレイアウトが大きく異なる文書や、複数の文書が結合されたPDFは、分類・抽出の設計が複雑になりやすいです。対象文書のバリエーションをあらかじめ把握し、どの処理方式が適切かを検討してから構築に入ることを推奨します。
DUは多様性のあるレイアウトに対応するための製品なので、もちろん対応可能なのですが、複雑な文書は設計難易度が上がるという事です。
学習データの質と量が重要
DUではドキュメントを機械学習できますが、学習データの質と量が低い場合、十分な精度が出ないケースもあります。学習データは抽出項目1件につき20-50件以上が推奨で、偏りが無く発生し得るフォーマットを網羅する必要があります。例えば「金額・請求先名・請求元名・支払期日・請求書番号」の5項目を抽出したい場合、100-250件の学習用サンプルデータが必要となります。
公式ドキュメント:Document Understanding ガイド
モダンとクラシックの違い
DUのプロジェクトタイプは、モダンとクラシックの2種類があります。どちらが優れているかではなく、要件によって使い分けるものです。
| 比較観点 | モダン | クラシック |
|---|---|---|
| 始めやすさ | ガイド付きで始めやすい | 仕様の理解が必要 |
| 自由度 | 標準的な構成が中心 | 細かく組み合わせて柔軟に対応 |
| コスト | 1ページ処理するごとに定額(OCR・分類・抽出をまとめて1課金) | 使った機能ごとに別々に課金(何を組み合わせるかで金額が変わる) |
| 推奨対象 | 初心者・標準ユースケース | 高度なカスタマイズ・既存資産活用 |
モダンは初心者向けで学習コストが低く、クラシックはカスタマイズでより柔軟な対応が可能なんですね!
モダンの特徴
モダンは、ガイドに沿って進めるだけでモデル構築ができる設計になっており、DUを初めて触る方でも迷いにくい構成になっています。
学習コストが低い
画面の案内に沿って進めるだけでモデルが構築でき、抽出器や分類器の仕組みを深く理解していなくても作業を始められます。
アクティブラーニングの仕組み
モダンでは、DUポータル上でAIが文書の自動アノテーションや、優先的にラベル付けすべき文書の推薦を行います。これにより、学習データ準備の手間を減らしながら、効率よくモデルを改善できます。
コストが予想しやすい
1ページあたり定額の課金なので、処理量が決まれば費用をシンプルに試算できます。
クラシックの特徴
クラシックは、より高度な設計が可能です。モダンと比べて設計の自由度が高く、要件が複雑になるほど強みが出ます。
コスト最適化
クラシックは使う機能ごとに課金されるため、シンプルな文書にはフォーム抽出器(低コスト)、複雑な文書には機械学習抽出器、といった使い分けができます。モダンは全ページ同一料金なので、文書の種類によってはクラシックのほうがコストを抑えられる場合があります。
組み合わせの柔軟さ
クラシックでは、分類器や抽出器を自分で選んで組み合わせられます。文書の特性に合わせて部品を選ぶので、設計の手間はかかりますが、その分だけ処理の精度やコストをコントロールしやすくなります。
モダンプロジェクト内でクラシック型の抽出器などを混在利用する場合は、クラシック側の課金も発生しうる点に注意が必要です。
Document Understandingのユースケース3選
DUが実際にどう使われているかを3つの例で紹介します。
請求書の読み取りと会計システム連携
請求書から請求書番号、日付、金額、取引先名などの項目を自動で抽出し、会計システムへの登録処理や仕訳補助につなげる用途です。UiPathには日本の請求書に対応した事前学習済みモデル(Invoices Japan)が提供されており、学習コストを抑えて始めやすい領域です。
電子帳簿保存法対応に向けた請求書・領収書のデータ化
請求書や領収書の画像・PDFから、取引先名、日付、金額などの情報を読み取り、保存情報の整理や前工程の効率化に活用する用途です。DUは証憑の読み取りや項目整理を自動化するための手段として機能します。
申込書や本人確認書類の情報転記
氏名、住所、生年月日、書類番号などを、申込書や運転免許証・マイナンバーカードなどの本人確認書類から読み取り、システムへの転記を支援する用途です。UiPathにはIDカード(日本語対応を含む)の事前学習済みモデルも用意されており、手入力削減や確認工数の削減に活用されています。
Document Understandingの費用
DUのコストは、ライセンス体系によってAIユニット(Flex Planの場合)と、プラットフォームユニット(Unified Pricing Planの場合)があります。どちらの体系かは、ご契約内容によって決まります。
モダンDUのコスト
まずはモダンのコスト表です。
| 操作 | Flex Plan(AIユニット) | Unified Pricing(プラットフォームユニット) |
|---|---|---|
| 通常実行(分類・抽出・OCR込み) | 1 AU | 0.2 PU |
| 生成AI検証機能 | 1 AU | 0.2 PU |
| 学習(トレーニング) | 無料 | 無料 |
| サービング(モデル公開) | 無料 | 無料 |
※2026-04-11時点のUiPath公式情報に基づく
クラシックDUのコスト
| 機能 | Flex Plan(AIユニット) | Unified Pricing(プラットフォームユニット) |
|---|---|---|
| UiPath Document OCR (※1) | 無料 | 無料 |
| キーワード分類器 | 無料 | 無料 |
| インテリジェントキーワード分類器 | ページ課金 | ページ課金 |
| マシンラーニング分類器 | ページ課金 | ページ課金 |
| 正規表現抽出器 | 無料 | 無料 |
| フォーム抽出器 | 0.2 AU | 0.04 PU |
| マシンラーニング抽出器 | 1 AU | 0.2 PU |
※1 外部OCR(Google Cloud Vision、Microsoft Azure OCRなど)を使用する場合は、それぞれ別途ライセンスが必要です。
ページ課金の詳細
「インテリジェントキーワード分類器」と「マシンラーニング分類器」は、ページ数によって料金が変わります。ページ数とは、ドキュメント1枚あたりの総ページ数を指します。
| ドキュメントのページ数 | Flex Plan(AIユニット) | Unified Pricing(プラットフォームユニット) |
|---|---|---|
| 1-25 | 0 | 0 |
| 26-50 | 1 | 0.2 |
| 51-75 | 2 | 0.4 |
| 76-100 | 3 | 0.6 |
| 101-125 | 4 | 0.8 |
| 125以上 | 5 | 1 |
公式ドキュメント:使用状況の測定と請求ロジック(フレックス プラン)
公式ドキュメント:使用状況の測定と請求ロジック (ユニファイド プライシング)
1000ページ処理のコスト試算
イメージをつかむための試算例です。
| 処理パターン | Flex Plan | Unified Pricing |
|---|---|---|
| モダンで1000ページ | 1000 AU | 200 PU |
| クラシック1000ページ(フォーム抽出器) | 200 AU | 40 PU |
| クラシック1000ページ(マシンラーニング抽出器) | 1000 AU | 200 PU |
まとめ
DUは「抽出器の総称」ではなく、デジタル化→分類→抽出→検証という文書処理全体の枠組みです。
以下のポイントを押さえておくと、実践しやすくなりますよ。
- 最初は請求書や領収書など、シンプルなドキュメントから始めるのがお勧めです。
- モダンとクラシックは要件によって使い分けましょう。初心者はモダンから始めるのがお勧めです。
- コストはプランと構成で変わります。事前にコストを試算してから始めましょう。